自然語言處理(NLP)_語言模型和主題模型
一、語言模型
舉個語言模型的例子:「今天我要去跑步。」我們可以把跑步替換成任何動詞,「今天我要去跳舞」或「今天我要去旅行」,這些替換都不成問題,但若是切換成形容詞:「今天我要去溫暖的」,我們人類很容易就會知道,這句話很怪,好像缺了什麼。
再來,常出現的問題就是語法結構分析(parsing),舉個例子:「今天我要去跑步」若被改成「跑步我今天要去」,這句話還是能理解,只是作為中文母語人士會覺得這句話超怪。而若是直接變成「跑步我要去今天」,這任何一個聽得懂中文的人應該都會很崩潰。因此,說出讓人能夠聽懂同時不覺得怪的一句話就是語言模型在做的事情。
寫出讓人理解的句子固然重要,還需要言之有理。首先,電腦需要決定這句話的內容,像是前面例子的關鍵內容是「時間」(今天)和「運動」(跑步);接著電腦會根據語法結構架構這句話,同時也會在字詞當中做選擇,像是「今天」的同義字就有「今朝」、「今日」,「跑步」也有些同義字如「小跑」、「飛跑」、「飛奔」。但電腦真的寫出:「今朝我要去飛奔。」那這台電腦還是需要重新訓練。
二、主題模型(Topic Model)
主題模型有兩個假設:
(1) 每個文件都混合著多個主題。
(2) 每個主題由多個字所組成。
根據不同的數學理論,主題模型的實作方法分為三:
(1)潛在語義分析 Latent Semantic Analysis (LSA)。
(2)概率潛在語義分析Probabilistic Latent Semantic Analysis (pLSA)。
(3)潛在迪利克雷分配 Latent Dirichlet Allocation (LDA)。
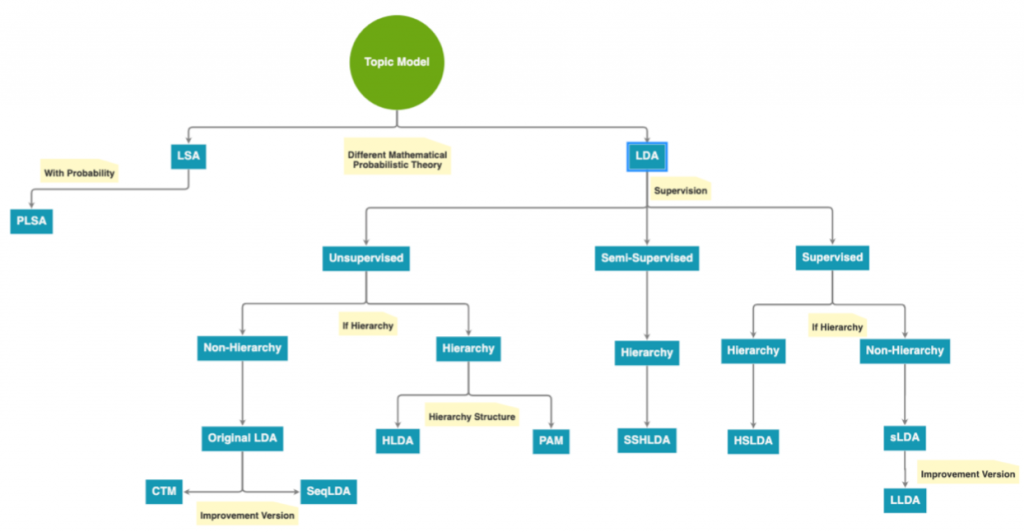
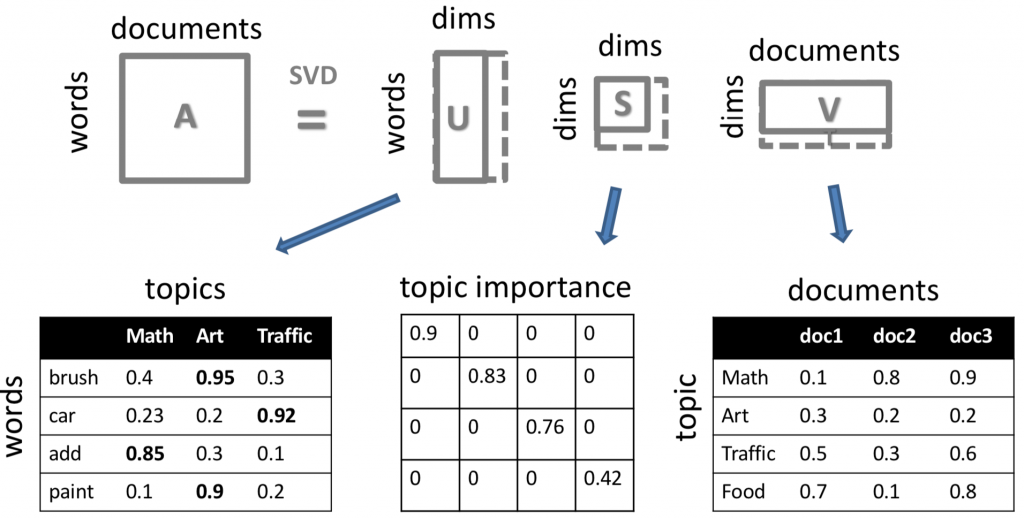
LSA主要比對了每個字與主題的關係(U)和每個主題和檔案的關係(V),如同下圖,”brush, car, add, paint”是每個曾經出現在文集中的字,”Math, Art, Traffic, Food”是可能的主題類別,而doc1, doc2, doc3則是每個文件。LSA的數學模型基於線性代數中的奇異值分解(Singular Value Decomposition),pLSA則在LSA的架構上加上了機率學,然而,pLSA容易出現過適的問題。之後,LDA在pLSA的基礎上加上貝氏定律,LDA和其演化版本們也是現在最主要主題模型的實作方法。
主題模型可以應用的層面非常廣,包含歷史資料、自然科學研究文章、社會科學研究等。針對這些應用,也有幾個重要課題像是怎麼將這些模型視覺化、如何讓非電腦科學背景的人更直觀的理解模型。
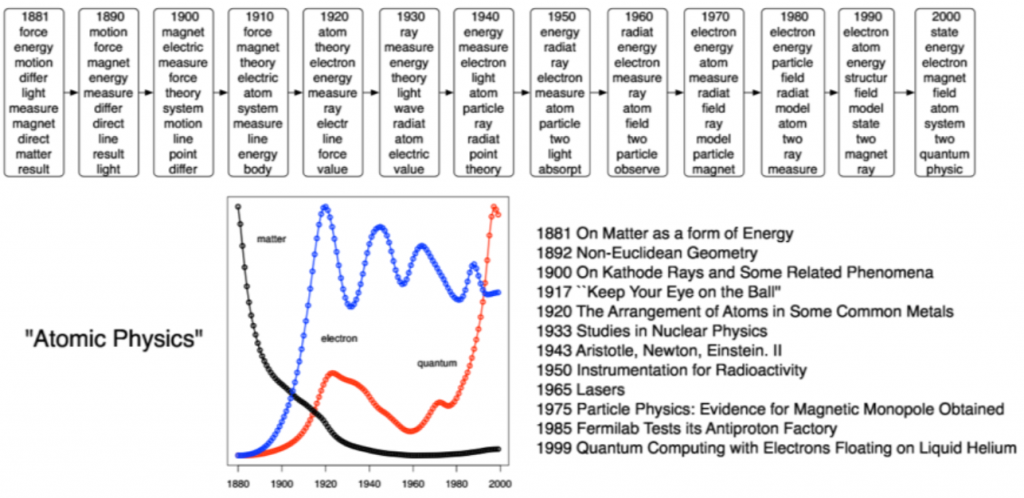
舉些實際應用上的例子:在下面這張圖中,可以知道隨著時間的推進,在原子物理學領域中研究主題的變化。
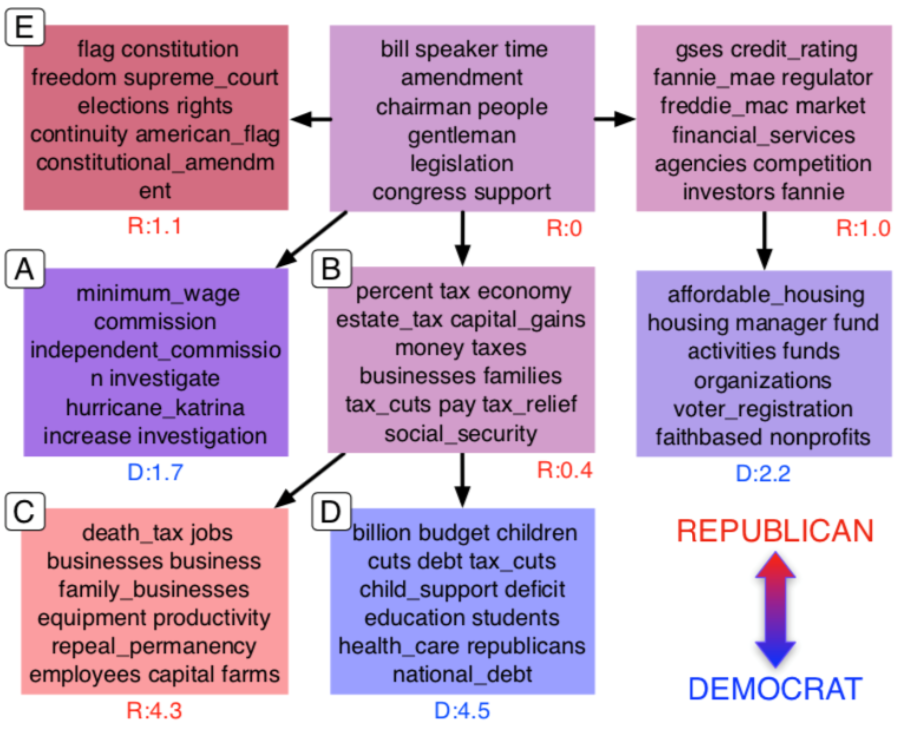
下圖中我們也能了解,美國兩大黨派對於各項議題的政治光譜。



沒有留言:
張貼留言
歡迎各方朋友針對本文議題討論~